GenAI & Applied LLM Expertise
We specialize in developing RAG/CAG solutions that leverage GenAI and Large Language Models (LLMs). Our approach makes LLMs work securely, efficiently, and with measurable impact on your business.

Build Intelligent Business Apps With Retrieval and Caching
Talk to an Expert60-80%
Reduction in LLM API Cost
10- 50x
Reduction in Response Latency
90%
Improved User Experience
75%
Faster Time-to-Value
Off-the-shelf AI models like GPT-4 and Claude are powerful, but without access to your internal data, they fall short of delivering precise, business-relevant insights. Generic responses, data blind spots, and security risks become major barriers to enterprise adoption.
At TestingXperts, we bridge this gap with Retrieval-Augmented Generation (RAG) and Cache-Augmented Generation (CAG), the cutting-edge techniques that make your large language models smarter, faster, and more aligned with enterprise demands. While RAG pulls the most relevant internal documents in real time, grounding AI answers in your data for enhanced accuracy and trust, CAG minimizes latency and compute costs by intelligently caching outputs, delivering faster responses and optimized performance. Our RAG/CAG AI development services help you build secure, high performance AI systems tailored to your domain, accelerating decision-making.





Accelerate decision-making with instant, context-rich insights at scale.
Cut AI operating costs while maximizing performance and precision.
Build customer trust with consistent, audit-ready intelligent responses.
Increase conversions and loyalty with hyper-relevant, real-time responses.
Launch AI-powered experiences faster with integrated enterprise-grade reliability.
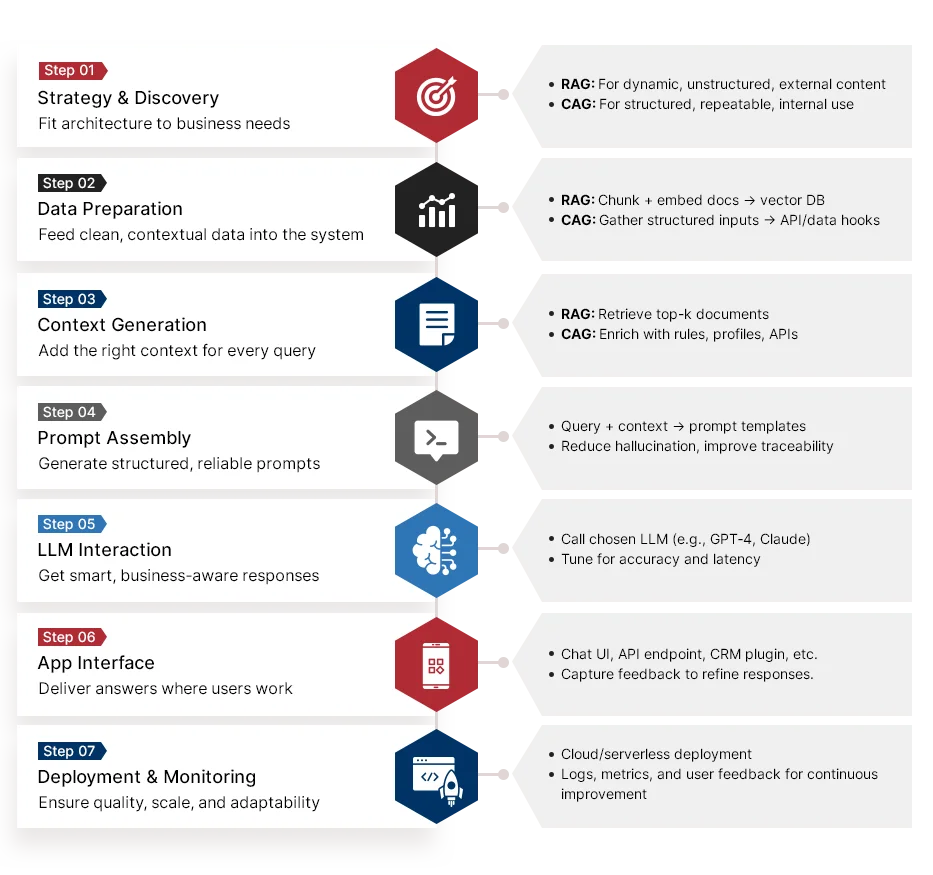
We help you design and deploy domain-specific RAG systems (e.g., naive RAG, rerank, agentic). Our approach involves leveraging frameworks like LangChain, LlamaIndex, and Haystack as per your business needs.
We help you build intelligent agents using AutoGen or CrewAI tools. These agents can plan and execute multi-step workflows based on retrieved knowledge.
We assist you in building LLM pipelines that dynamically inject user, system, or session context into prompts. This enhances accuracy, relevance, and trust in generated outputs.
We ensure secure RAG/CAG deployments by aligning with SOC2, GDPR, HIPAA, and ISO 27001. This includes access controls, data encryption, audit logging, and deployment on secure cloud, hybrid, or on-prem environments.
We automate knowledge-heavy tasks (e.g., document Q&A, support triage) by embedding RAG into tools like Slack, ServiceNow, Notion, or internal CRM.
We help you deploy containerized, serverless, or microservice-based architectures (Docker, Kubernetes, FastAPI). These architectures can scale with growing business demand.


We specialize in developing RAG/CAG solutions that leverage GenAI and Large Language Models (LLMs). Our approach makes LLMs work securely, efficiently, and with measurable impact on your business.
We manage the full lifecycle from use case discovery to deployment and optimization. Our expertise assists you in building context-aware chatbots or smart assistants without handoffs or delays.
We design RAG and CAG systems while keeping data privacy and compliance at the core of your requirements. Whether on-premises, cloud-native, or hybrid, we build according to your security standards.
We design context pipelines and retrieval logic by aligning with your workflows, KPIs, and domain language. Our team ensures your model responses are not only smart but also relevant.
RAG (Retrieval-Augmented Generation) ensures your AI applications provide reliable, context-aware responses by combining your data with advanced language models. Key benefits include:
Yes. Your data sources, business processes, and workflows are what RAG and CAG systems are built around. This includes bespoke ingestion pipelines, domain-specific embeddings, access controls, and response logic that fits with how your teams really function.
RAG and CAG cut costs by minimizing needless LLM calls and token use. Cached responses, selective retrieval, and optimized prompts reduce the cost of inference while keeping the quality of the responses high, especially enterprise AI workloads that process a lot of data.
Initial RAG deployments can start giving results in a few weeks. Teams generally observe instant improvements in answer accuracy, response relevance, and user trust once data sources are integrated and indexed. They don’t have to retrain big language models.
Retrieval-Augmented Generation (RAG) works with current data stores, APIs, and apps. Typical needs are secure data access, vector databases, LLM APIs, and middleware that link to your present architecture retrieval, generation, and business logic.
TestingXperts combines smart prompt design, cache-augmented generation, and optimal retrieval algorithms. This reduces repetitive LLM calls, speeds up response times, and keeps inference costs steady as more people use it in business apps.





Get a Consultation
Speak directly with a Digital Engineering Director.
Get solutions tailored to your unique development challenges.
Identify AI-driven development opportunities and build a roadmap for success.