Artificial intelligence (AI) and Machine Learning (ML) have drastically changed the dynamics of the global business ecosystem. As a result, the demand for high-quality and accurate datasets is also increasing. However, due to privacy concerns and limited availability, collecting real data is often challenging and requires optimal test data management strategy. According to statistics, up to 50% of the average QA time is spent waiting for high-quality test data or generating it.
That’s where synthetic data comes into the picture. If we consider the current software development and QA scenario, the testing process must be faster and earlier in the SDLC to support Agile transformation. According to a report, 75% of testing experts will use AI to generate environments and synthetic test data. But how does it fuel the Agile processes? What benefits can businesses expect from it?
What is Synthetic Test Data?
Synthetic test data is generated by AI techniques like deep learning and Generative AI that use real data. It imitates data from the production environment and is helpful for both automated and exploratory testing. QA engineers use synthetic data to work on more unique data without creating it manually. Generally, the data in the production environment is bigger than in the test environment. Testers can check for scenarios and code paths for unique outcomes before releasing the application.
Testers can use scripts and tools to generate synthetic test data during automated tests. This will help them fine tune test data management strategy and help find edge case bugs missed by legacy production data.
Understanding Test Data: Production vs. Synthetic
Aspect
Production Test Data
Synthetic Test Data
Data Accuracy
Production test data is highly accurate because it is taken from actual users.
Synthetic test data mimics real data but does not contain information about actual user records.
Privacy Risks
Even with data masking, the chances of exposing personal or sensitive data are always high.
As no real user data is taken, synthetic data has close to zero privacy concerns.
Compliance
Leveraging real data brings various compliance concerns like HIPAA, GDPR, and red tape into the test cycles.
There are no legal headaches, audits, or approvals associated with synthetic data.
Availability
Production test data is limited in availability, and users must wait for data dumps, redact information, or get permissions.
Synthetic data is always available as testers can generate what they need and when they need it.
Edge Cases Coverage
Real data does not always cover every edge case or worst-case scenario.
Synthetic data is completely under user control, as they can intentionally build edge cases into the data.
Testing Flexibility
There’s limited flexibility as users have to work with what they have, and sometimes, it may not even match testing requirements.
The testing process is tailored to the user’s needs, as they can design the exact data needed for every test.
Production Leaks Risks
Production leaks are highly likely, as a single slip-up with real data can cost millions.
No production leak risk associated with synthetic data. It is fake by design, so leaks don’t hurt.
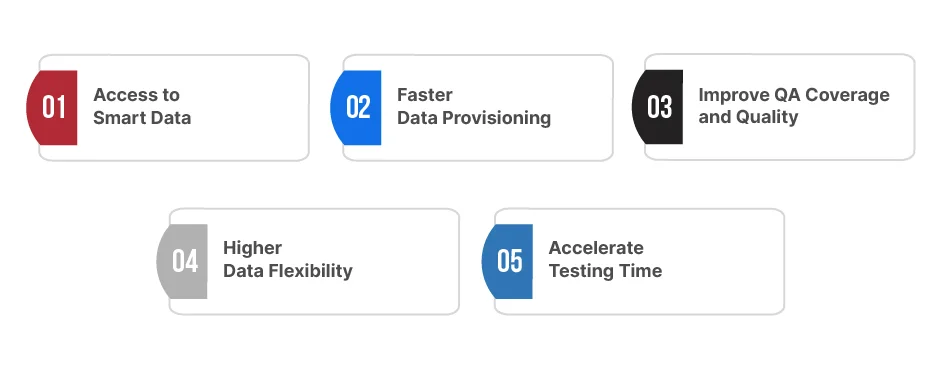
How Does Synthetic Test Data Benefit the Agile Delivery Process?
Mimicking test data offers excellent benefits for businesses, allowing them to improve their testing strategy. Here’s why you should consider selecting synthetic data for your next testing project:
Access to Smart Data:
High-quality synthetic data is crucial for developing digital products. AI’s powerful learning capabilities help synthetic data offer optimized test coverage with fewer bugs and higher reliability. Testers can mimic real customer data to improve CX with higher accuracy.
Faster Data Provisioning:
Unlike production data, synthetic data is quicker and a must-have for Agile SDLC. Users can simply use AI to accelerate data provisioning instead of spending hours building a dataset manually.
Improve QA Coverage and Quality:
Users can easily model edge cases, rare events, and negative paths to increase test coverage. To test system resilience, they can generate data with special characteristics, like malformed inputs.
Higher Data Flexibility:
QA engineers can adjust the data size to match their QA needs. They can generate data for any stage or environment without waiting on external systems, enabling earlier testing in the Agile lifecycle.
Accelerate Testing Time:
Synthetic data can be generated instantly by eliminating the need for real data and approvals. By leveraging independent datasets, QA engineers can simultaneously run multiple tests, speeding up iterations.
Implementing Synthetic Data in Agile Pipelines
Quality and control are some of the key aspects of synthetic data. To implement it in the Agile pipelines, one must understand its key characteristics that make it valuable for businesses:
Where to Introduce It: Unit, Integration, and End-to-End Tests
Synthetic data works across all levels of the testing pyramid. In unit tests, it helps verify individual functions with clean inputs. For integration tests, it provides structured datasets that test how services interact. In end-to-end testing, synthetic data allows full simulation of user journeys across systems.
It is often best to start in areas where data bottlenecks are causing the most friction. Once the value is proven, expansion across other test types becomes easier.
Automating Synthetic Data Generation in CI/CD
To fully benefit from synthetic data, it should be automated. Build it into your CI/CD pipelines, so each environment receives the right data at the right time. This removes manual effort and ensures consistency across teams.
Automation also enables ephemeral environments. When each test run gets a fresh synthetic dataset, there are no side effects or contamination from previous tests. This increases reliability and helps catch issues early.
Tools, Platforms, and Frameworks
A growing number of platforms specialize in synthetic data generation. Look for tools (like GenRocket) that integrate well with your existing stack and support structured data, tagging, and traceability. Version control and audit logs are also valuable for debugging and governance.
Many modern platforms offer templates, rule engines, and AI-powered data synthesis to speed up implementation. Choose solutions that let you scale while maintaining visibility and control.
Why Select Tx for Test Data Management Solutions?
At Tx, we offer customized QA consulting and implementation services to help organizations like yours modernize their testing practices. Our experts guide you through every STLC phase, from assessing current workflows to deploying synthetic test data across your Agile pipeline. We assist in designing test data strategies that align with your compliance requirements, industry regulations, testing strategies, and development processes.
Whether you are in the banking, healthcare, or insurance domain, our solutions fit your environment and scale as you grow. Our comprehensive test data management services ensure data integrity, availability, and security, enabling accurate and reliable testing outcomes. With our advanced automation capabilities and seamless tool integration, we help you enhance efficiency and accuracy in managing your test environments and data.
Conclusion
Synthetic test data is not just another component in your QA toolbox. It is a strategic asset that enables agility, protects customer trust, and reduces time-to-market. For decision-makers aiming to modernize their development practices, synthetic data offers a clear path to breaking free from the limitations of legacy testing. Businesses that make this shift today will be better equipped to deliver high-quality, secure, and compliant software tomorrow. Tx leverages its AI capabilities to generate synthetic test data and help you accelerate your software testing lifecycle, enabling you to deliver your products on time. To know how Tx can assist with test data management solutions, contact our software testing experts now.
Manjeet Kumar, Vice President at TestingXperts, is a results-driven leader with 19 years of experience in Quality Engineering. Prior to TestingXperts, Manjeet worked with leading brands like HCL Technologies and BirlaSoft. He ensures clients receive best-in-class QA services by optimizing testing strategies, enhancing efficiency, and driving innovation. His passion for building high-performing teams and delivering value-driven solutions empowers businesses to achieve excellence in the evolving digital landscape.
FAQs
What is test data management (TDM)?
Test Data Management (TDM) involves creating, maintaining, and managing the data needed for software testing. It ensures testers have the right data in the right format at the right time.
How is synthetic test data different from production data?
Synthetic test data is artificially generated and doesn’t come from real users. On the other hand, production data is actual user data pulled from live systems.
Why is synthetic data important in Agile and DevOps pipelines?
Synthetic data supports fast, automated testing by being instantly available, compliant, and customizable. It is perfect for rapid Agile and DevOps cycles.
How does synthetic test data enhance test coverage?
It allows testers to simulate edge cases, rare conditions, and various scenarios that might not exist in real-world data, boosting test completeness.
What are the benefits of synthetic test data in test data management?
Synthetic data improves data privacy, speeds up test cycles, reduces dependency on production data, and helps simulate complex test scenarios easily.
Why choose synthetic data over production data?
Synthetic data avoids privacy risks, is easier to generate, and can be shaped to match any testing need, unlike production data, which has access and compliance limitations.
What tools are available for synthetic data generation and TDM?
Popular tools include Tonic.ai, Mockaroo, Delphix, and IBM InfoSphere Optim. These tools offer ways to generate, manage, and mask test data.
Can synthetic test data be used across all test levels?
Yes, synthetic data works well across unit, integration, system, and performance testing, providing flexibility and control at every stage.
Why is synthetic data important for LLM testing?
Synthetic data helps test large language models with controlled, diverse, and bias-free inputs, which are critical for evaluating model behavior and fairness.
Can LLMs themselves generate synthetic test data?
Yes, LLMs can generate synthetic data by creating realistic and varied inputs, making them a valuable tool for automating test data creation.