Recommended Blogs

From Pilots to Production: Building AI Architectures That Scale
Table of Content
- What Scalability Really Means in AI
- How Scalable AI Architecture Impacts Businesses
- Core Design Principles for Building Scalable AI Architecture
- Optimizing AI for Scalability Across Cloud and Edge Environments
- Emerging Trends in Scalable AI Infrastructure
- What Are the Best Practices for Scaling AI from Pilot to Production?
- Challenges in Scaling AI
- AI Infrastructure Considerations
- Why Choose Tx for Scalable AI
- Conclusion
Share On



Most AI initiatives start with a promise: a working proof-of-concept, a successful pilot, or early wins in productivity or customer engagement. But too often, that momentum fades. AI pilots stall, weighed down by fragile pipelines, runaway costs, model drift, and shadow IT.
The real challenge is no longer building AI, it’s scaling it.
This requires more than technology alone. It requires a strong architectural foundation, one that ensures data flows seamlessly, models integrate across systems, updates deploy predictably, and failures are contaied without disruption.
Scaling AI demands an architecture that is innovative, resilient, agile, and sustainable. In this blog, we’ll unpack what scalable AI really means and why getting it right is the difference between an AI experiment and enterprise success.
What Scalability Really Means in AI
Scalability in AI isn’t just running more models or processing more data. It’s about reliability and repeatability without breaking your system or budget.
At its core, scaling AI means shifting from isolated pilots to AI embedded across workflows, departments, and geographies. It means your AI systems can grow in capability and volume, without rewriting infrastructure or draining engineering resources whenever a new use case emerges.
Scalability touches everything:
- Data ingestion must handle different formats, sources, and volumes in real time.
- Model training and deployment need automation pipelines that adapt as datasets evolve.
- Inference must run seamlessly across devices, whether a cloud server crunching billions of records or an edge device responding in milliseconds.
- Monitoring and retraining should be proactive, not reactive.
Without scalability, AI stays stuck in a lab. Models break in production. Costs spiral. Teams burn out managing Frankenstein systems.
True scalability, on the other hand, unlocks compounding returns. One architecture supports many models. One success becomes a blueprint for others. That’s where it goes from proving a point to driving the business forward.
How Scalable AI Architecture Impacts Businesses
Scalable AI architecture isn’t just a technical advantage; it’s a multiplier.
When your AI systems scale, they stop acting like isolated tools and start running critical parts of your business. You’re no longer fixing one issue at a time, you’re creating a repeatable system that solves many problems faster, smarter, and at lower cost.
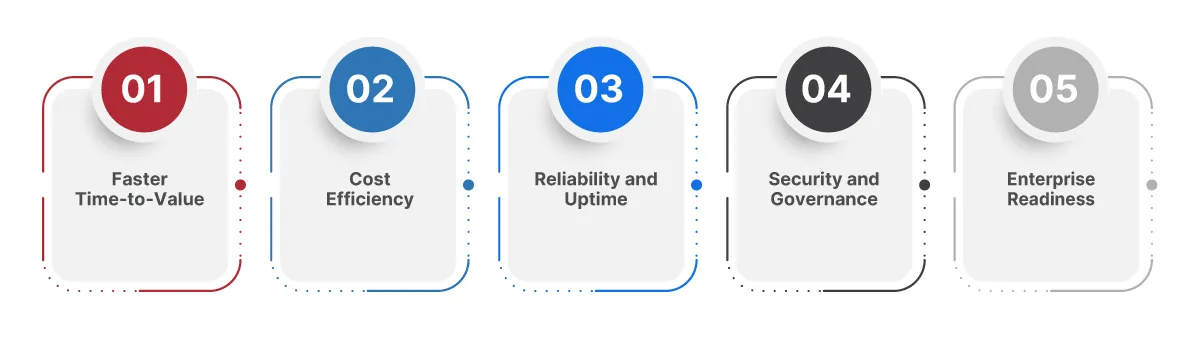
Here’s what that transformation looks like:
Faster Time-to-Value
Enterprises with scalable AI pipelines deploy models 3–5x faster than those stuck in manual handoffs and siloed systems. Automation in training, AI powered testing, and deployment drastically reduces cycle times.
Cost Efficiency
Instead of spinning up new infrastructure for every project, scalable architecture reuses components across teams like APIs, model registries, and data pipelines. It brings down operational overhead and cloud costs over time.
Reliability and Uptime
Systems designed with failover, version control, and monitoring baked in experience fewer outages. This matters when AI drives fraud detection, recommendations, or customer service at scale.
Security and Governance
A scalable architecture doesn’t judge AI wide; it keeps it compliant. Centralized model management helps track versions, enforce policies, and control access across teams.
Enterprise Readiness
According to Kore.ai, 71% of enterprises say architectural limitations are the top barrier to scaling AI beyond pilot projects, not skills, not data, but architecture.
The takeaway? Innovative models are only as good as the systems they run on. Scalable AI architecture enables businesses to turn isolated wins into repeatable, governed, enterprise-wide capabilities.
Core Design Principles for Building Scalable AI Architecture
You don’t get bigger by mistake. It needs systems that can be changed and run on their own. The following ideas make AI platforms that can grow and last without problems.

1. Modularity
Make systems into modules that can be used again. Models, data pipelines, APIs, and storage should all change independently. This speeds up deployment and encourages teams to utilize the same code again.
2. Infrastructure Abstraction
Separate the model layer and computational resources using orchestration tools and platform services. This separation makes the architecture flexible and future-proof, whether on-premises, in a hybrid cloud, or in many clouds.
3. Automated Lifecycle Management
Automate training, AI powered testing, deployment, and version control. MLOps pipelines and CI/CD for models ensure consistency and scale cutting deployment time dramatically.
4. Real-time Data Handling
Support streaming data, feature engineering, and low-latency inference from the ground up. Technologies like Kafka, Spark, and TensorRT often form the base of such architectures.
5. Observability & Feedback Loops
You need visibility into drift, performance, and system health. Monitoring systems must trigger retraining or alerts, so issues don’t snowball in production.
6. Security & Governance by Design
Embed access control, encryption, audit logging, and bias auditing from day one. As your deployment scales, so does your accountability.
7. Data Infrastructure & Quality
AI fails on weak data. According to a TechRadar feature, 75 % of initiatives that don’t scale struggle because of data variety and integration issues, not model shortcomings. Advanced data foundations reduce project failure rates.
8. Strategic Alignment & Enterprise Readiness
A Boston Consulting Group study found that only 26 % of companies have built the capabilities to move beyond pilots and generate real value from AI. Strategic intent and platform readiness matter more than just engineering prowess.
9. Proven Enterprise Patterns
An IDC-led study shows that for every 33 prototypes built, only 4 make it into production—an 88 % failure rate for scaling AI pilot projects. Systems built with lifecycle automation and integration in mind clear that gap.
These aren’t ideal. They’re shared by the organizations that succeeded in turning isolated AI proofs into enterprise capabilities. Apply them, and you’ll build architecture that scales AI across use cases, geographies, and business units.
Optimizing AI for Scalability Across Cloud and Edge Environments
Cloud is where most AI gets built. But in the real world, you must carefully decide where data is created. That’s when AI comes in. Both environments need to use a scalable architecture without any issues.
Cloud: The Best Place for AI Training
Cloud systems allow you to access power, storage, and other things. This makes them ideal for:
- Training large-scale models
- Managing datasets across regions
- Running centralized MLOps workflows
- Monitoring model performance and versioning
McKinsey reports that companies using cloud-native AI platforms have cut their model deployment time by nearly 40 percent.
Edge: Where Inference Happens in Real Time
AI at the edge is all about being responsive, independent, and private. It powers use scenarios when latency or connectivity in the cloud slows things down. This includes:
- Real-time diagnostics in medical devices
- Predictive maintenance on factory floors
- Vision-based systems in retail and logistics
Gartner estimates that by 2026, over 55 percent of AI data analysis will happen at the edge. That’s a sum of less than 10 percent in 2021
The Need for Unified Architecture
The smartest approach isn’t choosing cloud or edge. It’s a built AI pipeline that connects both:
- Use the cloud for training and central governance
- Deploy optimized, containerized models to edge devices
- Send real-time data and edge performance back for retraining
Frameworks like ONNX Runtime, TensorFlow Lite, and NVIDIA Triton make this loop possible. Kubernetes and service mesh tools manage deployment across cloud, edge, and everything.
This is where scalability shines. When your AI system adapts to different environments without breaking workflows, you’re not scaling tech, you’re scaling your intelligence.
Emerging Trends in Scalable AI Infrastructure
AI is evolving fast and the infrastructure powering it must evolve just as fast. Enterprises are no longer experimenting; they’re under pressure to operationalize AI at scale.
As the tech stack shifts from pilots to enterprise-grade deployment, new infrastructure trends are defining how scalable AI will be designed, governed, and optimized in the years ahead.

Composable AI Platforms
Instead of relying on monolithic tools, organizations are adopting composable AI platforms. These let teams plug in best-in-class components for data prep, training, AI powered testing, and deployment. This modularity increases agility and helps scale across use cases without being locked into a single vendor.
Hybrid and Multicloud Architectures
Companies are using multiple clouds. Now, AI systems must run on AWS, Azure, Google Cloud, and private data centers. Scalable AI infrastructure lets you use it in hybrid environments, ensuring the system is strong, cheap, and follows the rules.
AI Model Ops and Feature Stores
With more models in production, managing versions, inputs, and features becomes complex. Feature stores and model registries are becoming core infrastructure. They centralize model assets and streamline governance.
Serverless AI Workloads
AI is starting to use serverless computing. It allows teams to use functions and models without having to worry about the servers that run them. This makes infrastructure cheaper and easier to modify the scale of workloads based on what people need. It’s ideal for workloads that require a lot of inference and have spikes that aren’t always easy to predict.
AI-Specific Hardware Acceleration
From GPUs and TPUs to AI-optimized chips like NVIDIA Grace Hopper and Intel Gaudi, hardware is purpose-built to support scaled AI. These advances are improving performance while keeping energy consumption and costs in check.
Federated Learning and Decentralized AI
In regulated industries, data can’t be centralized. Federated learning allows models to train across distributed devices or silos without sharing raw data. This trend is becoming key to scalable AI in sectors like finance and healthcare.
Sustainability in AI Infrastructure
Scalability also includes efficiency. Green computing is becoming a part of architectural decisions since AI workloads use a lot of energy. Companies are investing money in scheduling that considers carbon and eco-friendly technology. This makes their data centers work better.
What Are the Best Practices for Scaling AI from Pilot to Production?
To go from a successful pilot to enterprise deployment, you need more than just training a good model. AI productionization requires solid pipelines, governance, and infrastructure that can scale across teams and use cases.
Key AI scaling best practices include:
Standardize Data Pipelines
Reliable data ingestion is what enables machine learning systems to grow. Use centralized pipelines that can handle both structured and unstructured data across all departments.
Adopt MLOps Pipelines
Automated CI/CD for models makes it easier to handle training, testing, and deployment. It also speeds up upgrades and reduces the need for human labor.
Design A Modular AI Architecture
With a modular corporate AI architecture, models, APIs, and data layers can all change independently. This makes it easier to deal with new AI use cases.
Implement Versioning And Governance
Use registries and governance structures to keep track of model versions, datasets, and experiments. This prevents conflicts during deployment and makes it easier to find things.
Plan Infrastructure For Scale
AI pilots typically have to work with limited resources. In production applications, distributed systems must handle real-time inference, massive datasets, and multiple models simultaneously.
When these strategies are used together, businesses may move from small tests to a full AI rollout that helps the firm grow over time.
Challenges in Scaling AI
Scaling AI raises operational and technological challenges that don’t always surface when you first try it out.
Data Management Complexity
AI systems need to work with a wide range of data from across the organization. The most common problems that prevent AI from moving from pilot to production are poor data quality and broken pipelines.
Model Optimization And Drift
Models may not be as accurate as they used to be as real-world data changes. To keep AI systems reliable, you need to monitor them and retrain them.
Resource Allocation And Infrastructure Costs
AI workloads require significant computing power, such as GPUs and distributed clusters. Without careful planning, the costs of using the cloud can rise dramatically.
Integration With Enterprise Systems
AI for production has to work with APIs, old systems, and business platforms. Integration problems can make it take longer to install AI and make it less likely to be used.
Governance And Compliance Risks
When using AI at scale, it is important to keep things clear, safe, and in line with the law. This is especially important in the fields of banking, health care, and insurance.
Companies that address these problems early are better able to design an AI infrastructure that can grow and support long-term innovation.
AI Infrastructure Considerations
Infrastructure is an important part of modernizing enterprise AI architecture. The right technological stack will determine whether AI systems can adapt as demand rises.
Cloud Platforms For AI Workloads
Most major cloud providers offer environments that can scale to handle model training and deployment. AWS, Azure, and Google Cloud are examples of platforms that offer managed services for AI lifecycle management, GPU processing, and data pipelines.
Distributed Computing Frameworks
Technologies like Spark and Ray enable processing enormous amounts of data and training multiple models simultaneously. These frameworks help machine learning systems handle large datasets and grow.
Containerization And Orchestration
Kubernetes and other tools help ensure that AI models are deployed consistently across environments. Containers let teams spread workloads across cloud, hybrid, and edge infrastructure.
Cost Optimization Strategies
By using approaches such as efficient workload scheduling, auto-scaling clusters, and model compression, you can significantly reduce infrastructure costs without sacrificing performance.
Companies that invest in the right infrastructure can grow their AI systems without repeatedly rewriting their technology stack.
Why Choose Tx for Scalable AI
Scaling AI isn’t difficult, but it’s a long-term promise. At Tx, we understand that not everyone can use the same AI structure. It must adapt to meet your goals, industry, and data. Here is why we are different:
Quality Engineering using AI First
Our approach integrates AI enabled testing, validation, and tracking into your lifecycle. We build MLOps pipelines that catch drift early, test inference accuracy across environments, and automate retraining triggers so your models stay robust at scale.
Platform-Agnostic Scalability
Our teams create and improve architecture that works in your setting, whether on Azure, AWS, a hybrid edge, or a cluster in your building. We don’t simply pick the correct tools; we also ensure they all perform well on a large scale.
Enterprise-Ready Governance
Our architectural patterns already include security, compliance, and performance monitoring. We help businesses scale AI responsibly, from making models easy to understand to tracking audits and backup plans.
Cross-Domain Experience
From healthcare to finance, logistics to manufacturing, we’ve delivered AI solutions that transitioned from pilot to full enterprise rollouts. Our domain expertise helps accelerate adoption and reduce rework.
Continuous Optimization
Scaling doesn’t make deployment the same for everyone. We stay involved to monitor the system’s health, improve the pipelines, and help the model evolve. This makes sure that your AI infrastructure stays in sync with your business.
Conclusion
AI doesn’t fail because models are weak. It fails because the architecture was never built to scale. Scalability is not a detail — it’s the foundation that turns pilots into business breakthroughs.
When your AI architecture enables modular design, hybrid cloud and edge flexibility, real-time feedback loops, and enterprise-grade governance, AI stops being an experiment. It becomes a force multiplier.
At TestingXperts, we help enterprises make that leap from promising pilots to scaled AI ecosystems. With AI-first engineering, intelligent testing, and deep domain expertise, we design architectures that grow with your ambition, not against it.
Ready to scale AI without hitting walls? Let’s architect your enterprise advantage.


Amar Jamadhiar
VP, Delivery North America
Amar Jamdhiar is the Vice President of Delivery for TestingXperts's North America region, driving innovation and strategic partnerships. With over 30 years of experience, he has played a key role in forging alliances with UiPath, Tricentis, AccelQ, and others. His expertise helps TestingXperts explore AI, ML, and data engineering advancements.
FAQs
How can we ensure that our AI models scale effectively from pilot to production?
- Build a modular AI architecture
- Automate pipelines with MLOps
- Implement monitoring and retraining
- Use a scalable cloud infrastructure
- Establish governance and model versioning
What is the scaling rule of AI?
The scaling rule of AI emphasizes designing systems that grow without breaking. One successful model or pipeline should be reusable, automated, and adaptable so that AI can expand across teams, applications, and regions without repeated manual effort.
How do you scale an AI model?
Scaling an AI model requires modular architecture, automated MLOps pipelines, and cloud-edge integration. It includes version control, monitoring, retraining, and efficient data handling to ensure consistent performance and reliable deployment across diverse environments.
How to measure AI success in your organization?
AI success is measured by business impact, deployment speed, model accuracy, cost efficiency, and system reliability. Key indicators include ROI, adoption across teams, reduction in manual effort, and the ability to scale AI capabilities consistently.
What challenges should we anticipate when scaling AI solutions?
Some common problems with scaling AI include data fragmentation, model drift, rising infrastructure costs, and integration with enterprise systems. Fixing these problems early makes enterprise AI more reliable and speeds up its rollout.
Which tools and platforms are best for scaling AI models?
Kubernetes is a popular platform for orchestration, MLflow for tracking models, TensorFlow Extended for pipelines, and Ray for distributed workloads. These tools help build machine learning systems that can grow and produce efficient AI output.
How do we measure AI model performance at scale?
Companies keep track of accuracy, latency, drift indicators, and how much of their infrastructure they use. These measurements help keep track of how reliable and cost-effective large-scale AI deployments are.
How can TestingXperts help scale AI models in production?
TestingXperts enables putting AI into production through MLOps testing, AI validation frameworks, and architectural evaluation. Our teams ensure that enterprise AI environments have scalable AI infrastructure, consistent model performance, and strong governance.
Discover more
